Last week at LinuxCon I gave a presentation on DevStack which gave me the proper excuse to turn an idea that Dean Troyer floated a year ago about OpenStack Layers into pictures (I highly recommend reading that for background, I won't justify every part of that here again). This abstraction has been something that's actually served us well as we think about projects coming into DevStack.
 Some assumptions are made here in terms of what essential services are here as we build up the model.
Some assumptions are made here in terms of what essential services are here as we build up the model.
Layer 1: Base Compute Infrastructure
We assume that compute infrastructure is the common starting point of minimum functional OpenStack that people are deploying. The output of the last OpenStack User Survey shows that the top 3 deployed services, regardless of type of cloud (Dev/Test, POC, or Production) are Nova / Glance / Keystone. So I don't think this is a huge stretch. There are definitely users that take other slices (like Swift only) but compute seems to be what the majority of people coming to OpenStack seem to be focussed on.
Basic Compute services need 3 services to get running. Nova, Glance, and Keystone. That will give you a stateless compute cloud which is a starting point for many people getting into the space for the first time.
Layer 2: Extended Infrastructure
Once you have a basic bit of compute infrastructure in place, there are some quite common features that you do really need to do more interesting work. These are basically enhancements on the Storage, Networking, or Compute aspects of OpenStack. Looking at the User Survey these are all deployed by people, in various ways, at a pretty high rate.
This is the first place we see new projects integrating into OpenStack. Ironic extends the compute infrastructure to baremetal, and Designate adds a missing piece of the networking side with DNS management as part of your compute creation.
Hopefully nothing all that controversial here.
Layer 3: Optional Enhancements
Now we get a set of currently integrated services that integrate North bound and South bound. Horizon integrates on the North bound APIs for all the services, it requires service further down in layers (it also today integrates with pieces further up that are integrated). Ceilometer consumes South bound parts of OpenStack (notifications) and polls North bound interfaces.
From the user survey Horizon is deployed a ton. Ceilometer, not nearly as much. Part of this is due to how long things have been integrated, but even if you do analysis like take the Cinder / Neutron numbers, delete all the Folsom deploys from it (which is the first time those projects were integrated) you still see a picture where Ceilometer is behind on adoption. Recent mailing list discussions have hints at why, including some of the scaling issues, and a number of alternative communities in this space.
Let's punt on Barbican, because honestly, it's new since we came up with this map, and maybe it's really a layer 2 service.
Layer 4: Consumption Services
I actually don't like this name, but I failed to come up with something better. Layer 4 in Dean's post was "Turtles all the way down", which isn't great describing things either.
This is a set of things which consume other OpenStack services to create new services. Trove is the canonical example, create a database as a service by orchestrating Nova compute instances with mysql installed in them.
The rest of the layer 4 services all fit the same pattern, even Heat. Heat really is about taking the rest of the components in OpenStack and building a super API for their creation. It also includes auto scaling functionality based on this. In the case of all integrated services they need a guest agent to do a piece of their function, which means when testing them in OpenStack we don't get very far with the Cirros minimal guest that we use for Layer 3 and down.
But again, as we look at the user survey we can see deployment of all of these Layer 4 services is lighter again. And this is what you'd expect as you go up these layers. These are all useful services to a set of users, but they aren't all useful to all users.
I'd argue that the confusion around Marconi's place in the OpenStack ecosystem comes with the fact that by analogy it looks and feels like a Layer 4 service like Trove (where a starting point would be allocating computes), but is implemented like a Layer 2 one (straight up raw service expected to be deployed on bare metal out of band). And yet it's not consumable as the Queue service for the other Layer 1 & 2 services.
Leaky Taxonomy
This is not the end all be all of a way to look at OpenStack. However, this layered view of the world confuses people a lot less than the normal view we show them -- the giant spider diagram (aka the mandatory architecture slide for all OpenStack presentations):
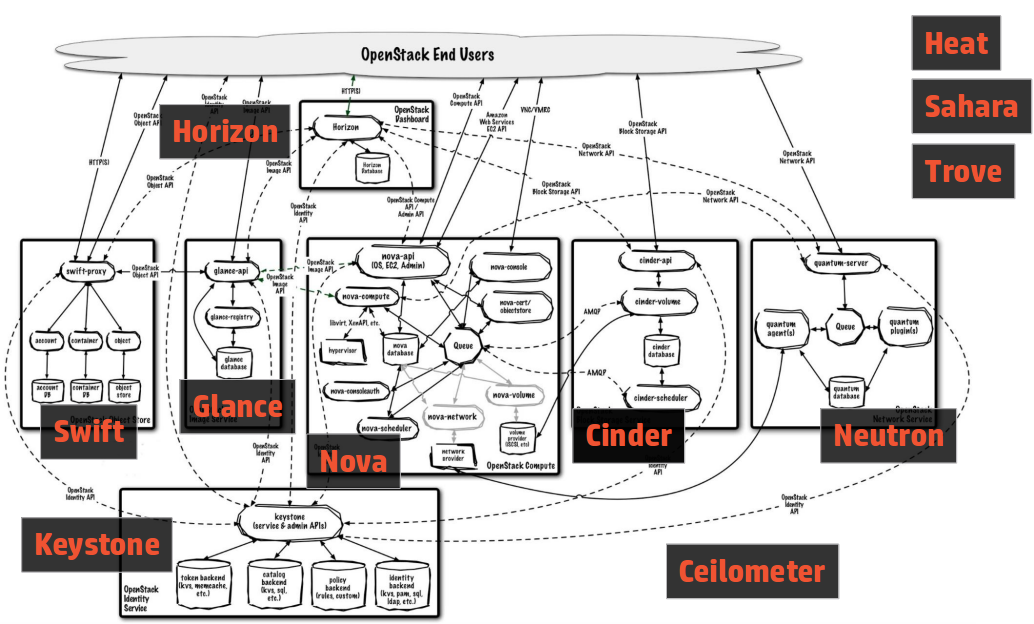 This picture is in every deep dive on OpenStack, and scares the crap out of people who think they might want to deploy it. There is no starting point, there is no end point. How do you bite that off in a manageable chunk as the spider grows?
This picture is in every deep dive on OpenStack, and scares the crap out of people who think they might want to deploy it. There is no starting point, there is no end point. How do you bite that off in a manageable chunk as the spider grows?
I had one person come up to me after my DevStack talk giving a big thank you. He'd seen a presentation on Cloudstack and OpenStack previously and OpenStack's complexity from the outside so confused him that he'd run away from our community. Explaining this with the layer framing, and showing how you could experiment with this quickly with DevStack cleared away a ton of confusion and fear. And he's going to go dive in now.
Tents and Ecosystems
Today the OpenStack Technical Committee is in charge of deciding the size of the "tent" that is OpenStack. The approach to date has been a big tent philosophy, where anything that's related, and has a REST API, is free to apply to the TC for incubation.
But a big Tent is often detrimental to the ecosystem. A new project's first goal often seems to become incubated, to get the gold star of TC legitimacy that they believe is required to build a successful project. But as we've seen recently a TC star doesn't guarantee success, and honestly, the constraints on being inside the tent are actually pretty high.
And then there is a language question, because OpenStack's stance on everything being in Python is pretty clear. An ecosystem that only exists to spawn incubated projects, and incubated projects only being allowed to be in Python, basically means an ecosystem devoid of interesting software in other languages. That's a situation that I don't think any of us want.
So what if OpenStack were a smaller tent, and not all the layers that are in OpenStack today were part of the integrated release in the future? Projects could be considered a success based on their users and usage out of the ecosystem, and not whether they have a TC gold star. Stackforge wouldn't have some stigma of "not cool enough", it would be the normal place to exist as part of the OpenStack ecosystem.
Mesos is an interesting cloud community that functions like that today. Mesos has a small core framework, and a big ecosystem. The smaller core actually helps grow the ecosystem by not making the ecosystem 2nd class citizens.
I think that everyone that works on OpenStack itself, and all the ecosystem projects, want this whole thing to be successful. We want a future with interoperable, stable, open source cloud fabric as a given. There are lots of thoughts on how we get there, and as no one has ever created a universal open source cloud fabric that lets users have the freedom to move between providers, public and private, so it's no surprise that as a community we haven't figured everything out yet.
But here's another idea into the pool, under the assumption that we are all smarter together with all the ideas on the table, than any of us are on our own.
 That's because first time up it needs to create a base configuration. Fortunately it's pretty straight forward what that needs to be.
That's because first time up it needs to create a base configuration. Fortunately it's pretty straight forward what that needs to be.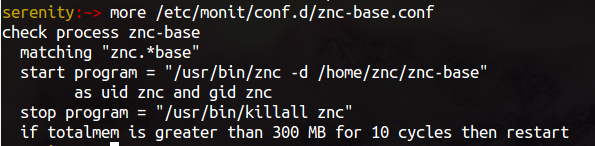 Because znc doesn't do pid files right, this just matches on a process name. It has a start command which includes the user / group for running this, and a stop command, and some out of bounds criteria. All in a nice little dsl.
Because znc doesn't do pid files right, this just matches on a process name. It has a start command which includes the user / group for running this, and a stop command, and some out of bounds criteria. All in a nice little dsl.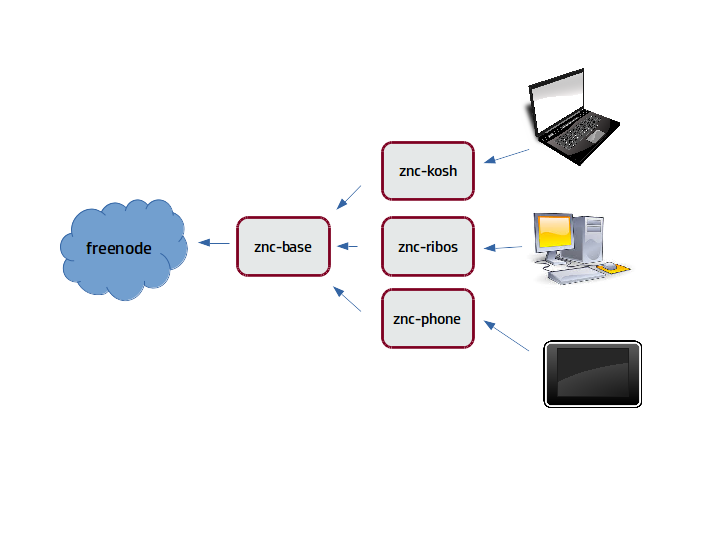 Which means that all devices have all the context for IRC, but I'm only presented as a single user on the freenode network.
Which means that all devices have all the context for IRC, but I'm only presented as a single user on the freenode network. While I am excited to read this myself, I had a moment where I got even more excited about the idea of my daughter discovering this book down the road.
While I am excited to read this myself, I had a moment where I got even more excited about the idea of my daughter discovering this book down the road. Step 2: reset the changes
git reset ##### will unstage all the changes back to the referenced commit, so I'll be working from a blank slate to add the changes back in. So in this case I need to figure out the last commit before the one I want to change, and do a git reset to that hash.
Step 2: reset the changes
git reset ##### will unstage all the changes back to the referenced commit, so I'll be working from a blank slate to add the changes back in. So in this case I need to figure out the last commit before the one I want to change, and do a git reset to that hash.
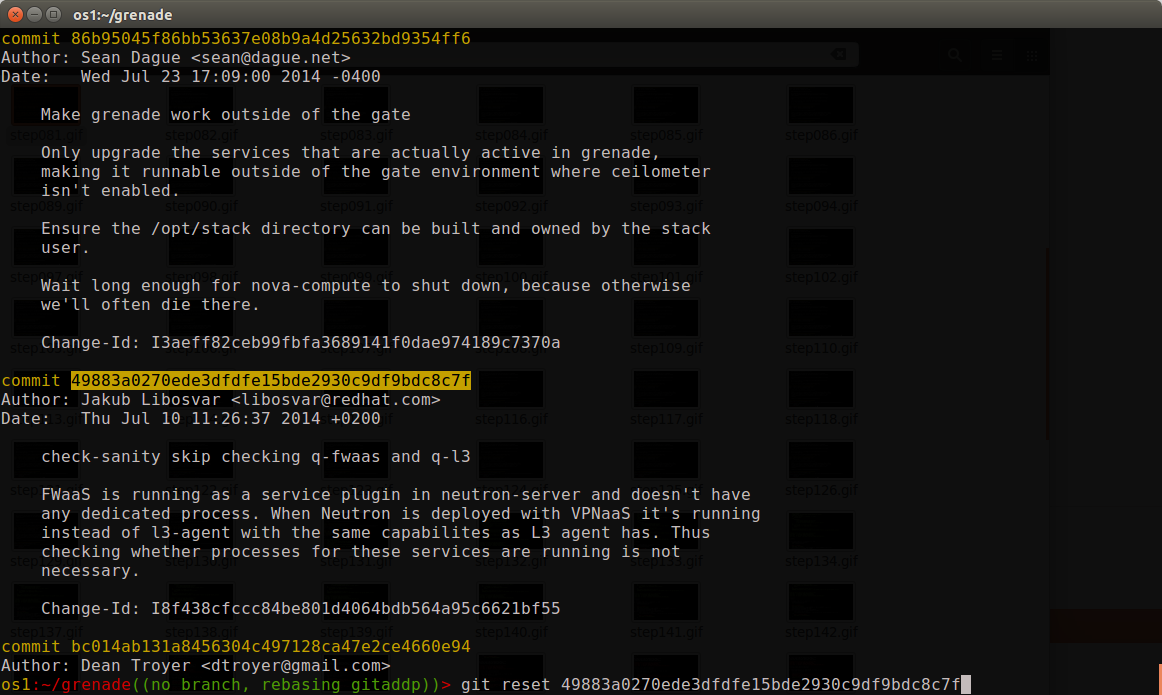 Step 3: commit in whole files
Unrelated change #1 was fully isolated in a whole file (stop-base), so that's easy enough to do a git add stop-base and then git commit to build a new commit with those changes. When splitting commits always do the easiest stuff first to get it out of the way for tricky things later.
Step 4: git add -p
In this change grenade.sh needs to be split up all by itself, so I ran git add -p to start the interactive git add process. You will be presented with a series of patch hunks and a prompt about what to do with them. y = yes add it, n = no don't, and lots of other options to be trickier.
Step 3: commit in whole files
Unrelated change #1 was fully isolated in a whole file (stop-base), so that's easy enough to do a git add stop-base and then git commit to build a new commit with those changes. When splitting commits always do the easiest stuff first to get it out of the way for tricky things later.
Step 4: git add -p
In this change grenade.sh needs to be split up all by itself, so I ran git add -p to start the interactive git add process. You will be presented with a series of patch hunks and a prompt about what to do with them. y = yes add it, n = no don't, and lots of other options to be trickier.
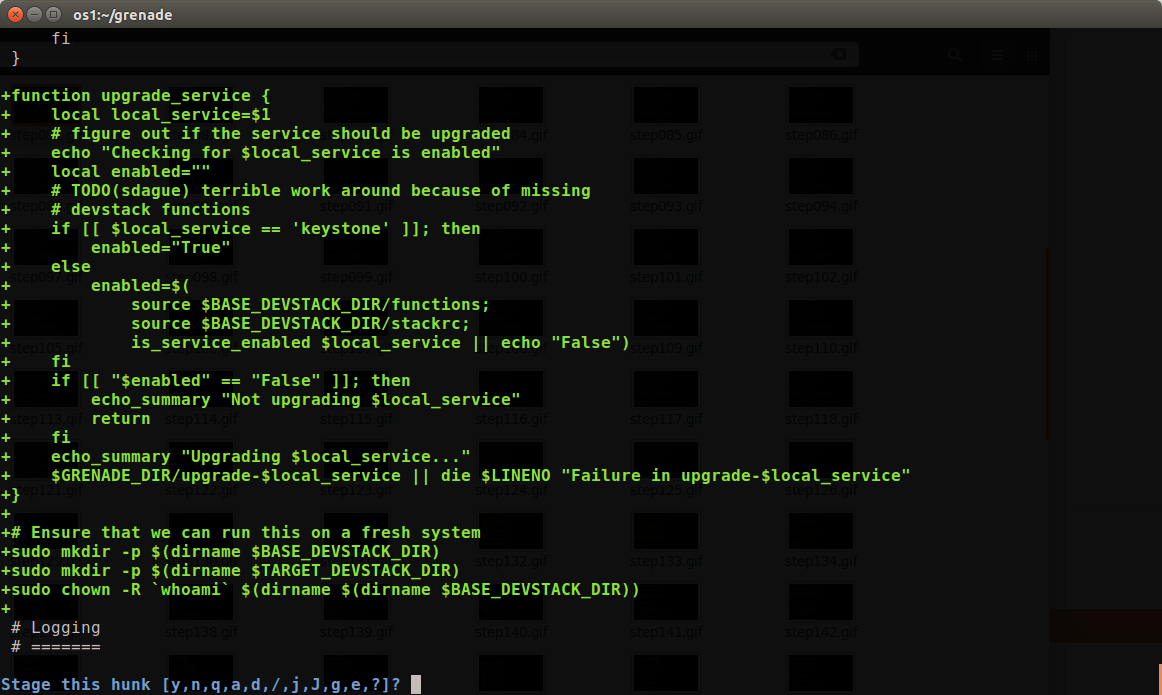 In my particular case the first hunk is actually 2 different pieces of function, so y/n isn't going to cut it. In that case I can type 'e' (edit), and I'm dumping into my editor staring at the patch, which I can interactively modify to be the patch I want.
In my particular case the first hunk is actually 2 different pieces of function, so y/n isn't going to cut it. In that case I can type 'e' (edit), and I'm dumping into my editor staring at the patch, which I can interactively modify to be the patch I want.
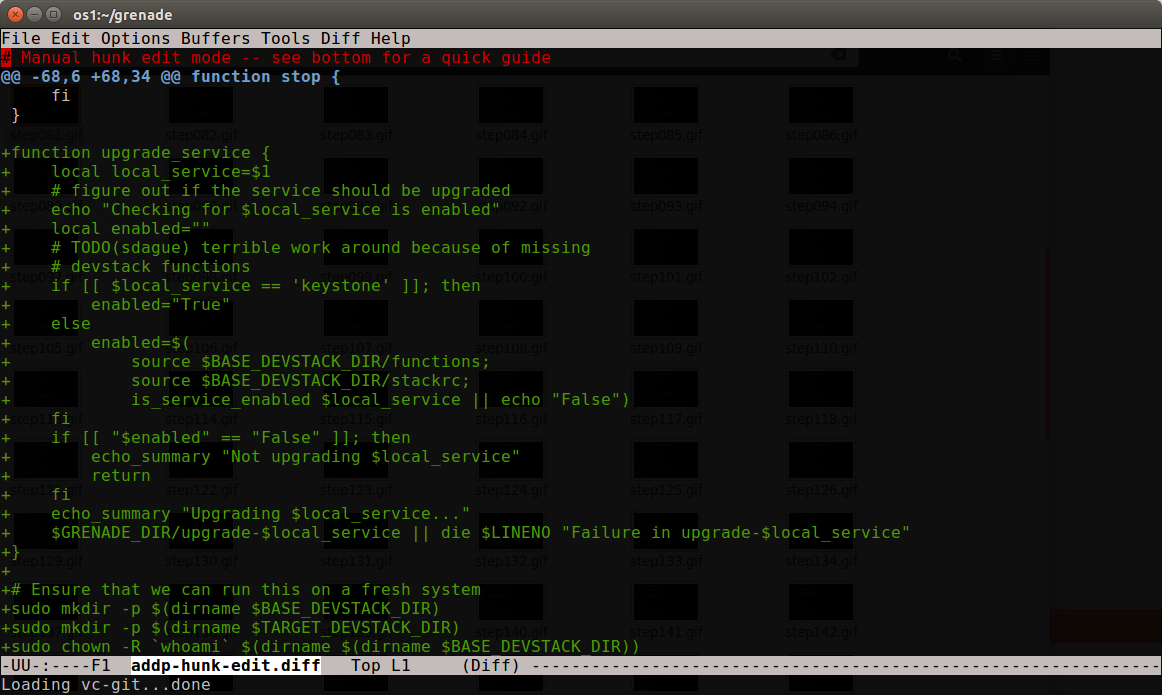 I can then delete the pieces I don't want in this commit. Those deleted pieces will still exist in the uncommitted work, so I'm not losing any work, I'm just not yet dealing with it.
I can then delete the pieces I don't want in this commit. Those deleted pieces will still exist in the uncommitted work, so I'm not losing any work, I'm just not yet dealing with it.
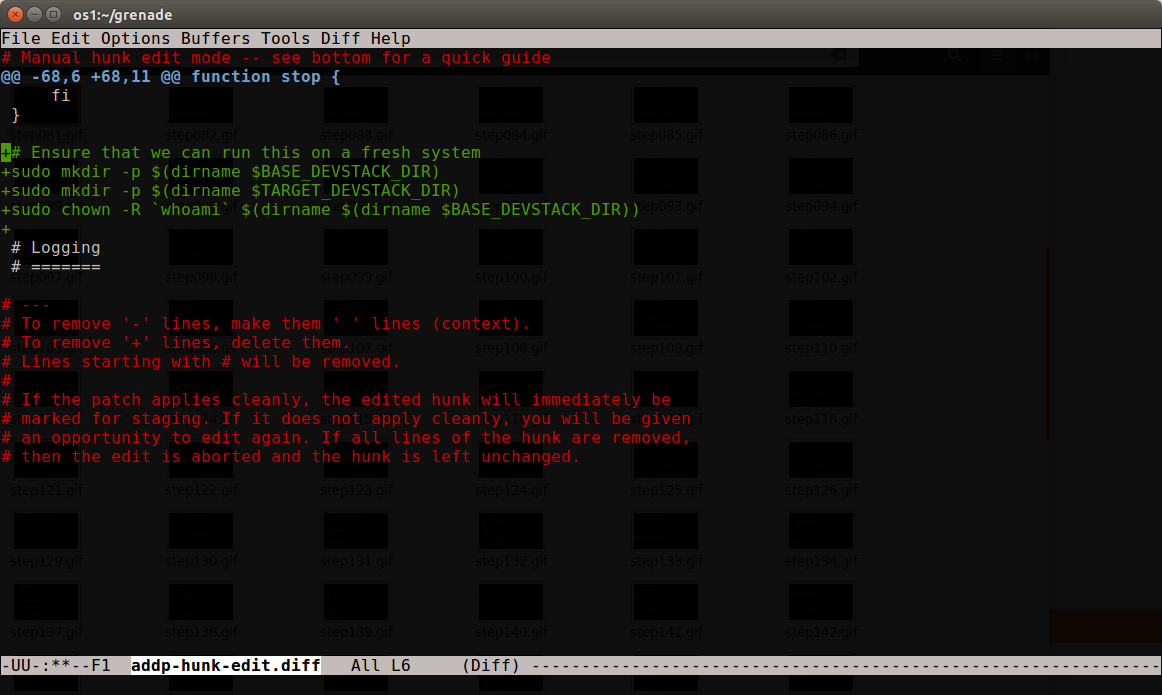 Ok, that looks like just the part I want, as I'll come back to the upgrade_service function in patch #3. So save it, and final all the other hunks in the file that are related to that change to add them to this patch as well.
Ok, that looks like just the part I want, as I'll come back to the upgrade_service function in patch #3. So save it, and final all the other hunks in the file that are related to that change to add them to this patch as well.
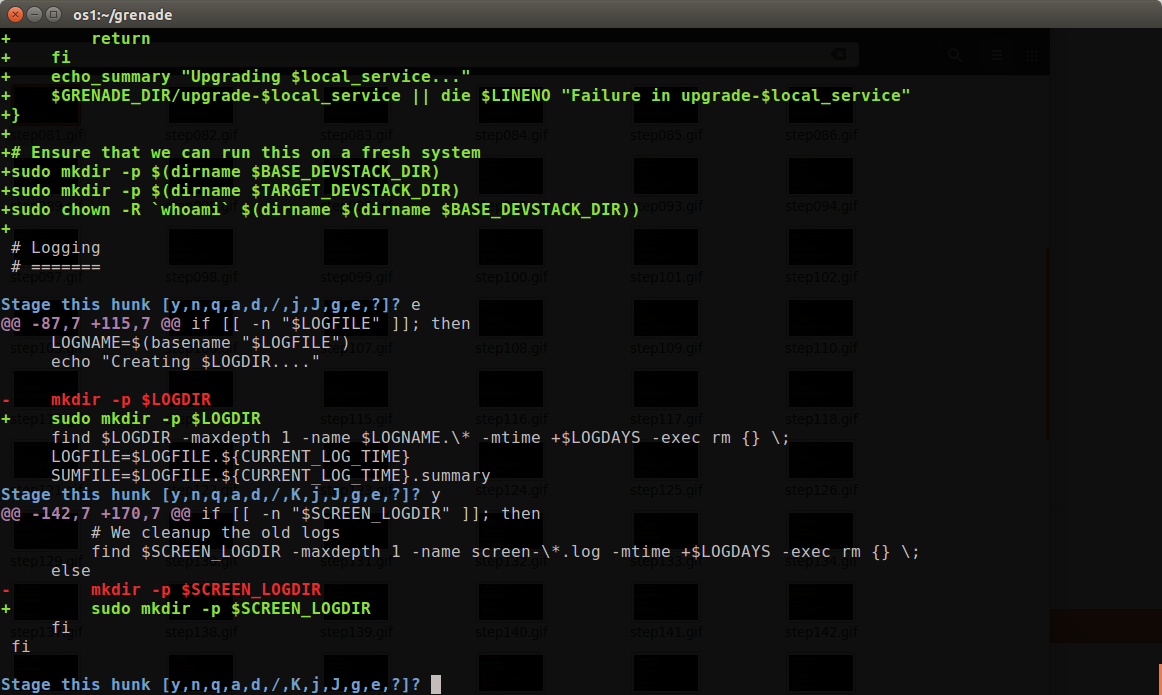 Yes, to both of these, as well as one other towards the end, and this commit is ready to be 'git commit'ed.
Yes, to both of these, as well as one other towards the end, and this commit is ready to be 'git commit'ed.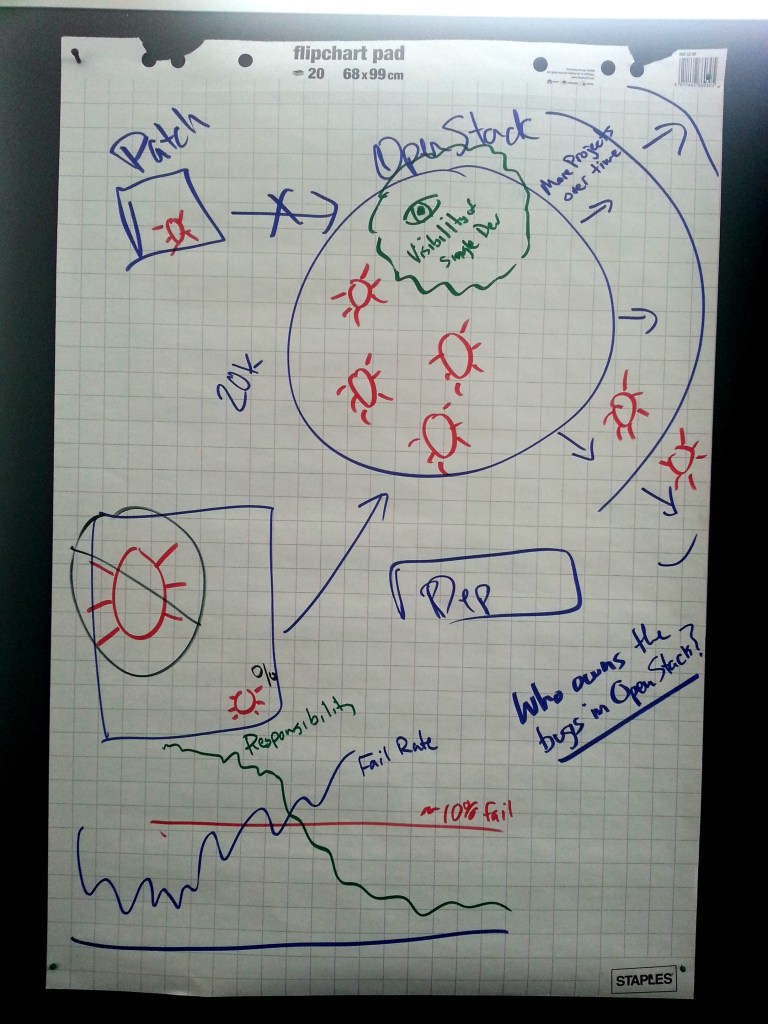 We have a system that's designed to merge good code, and keep bugs out. The problem is that while it's doing a great job of keeping big bugs out, subtle bugs, ones that are low percentage (like show up in only 1% of test runs) can slip through. These bugs don't go away, they instead just build up inside of OpenStack.
We have a system that's designed to merge good code, and keep bugs out. The problem is that while it's doing a great job of keeping big bugs out, subtle bugs, ones that are low percentage (like show up in only 1% of test runs) can slip through. These bugs don't go away, they instead just build up inside of OpenStack.

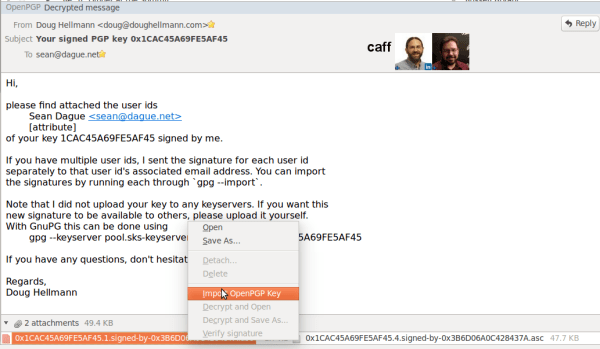 Once you've done this you'll have included the signature in your local database. Then from the command line you can:
Once you've done this you'll have included the signature in your local database. Then from the command line you can: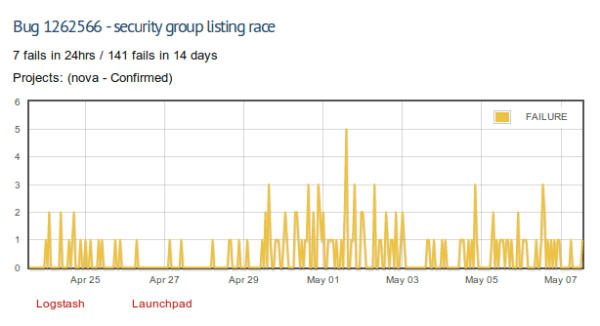
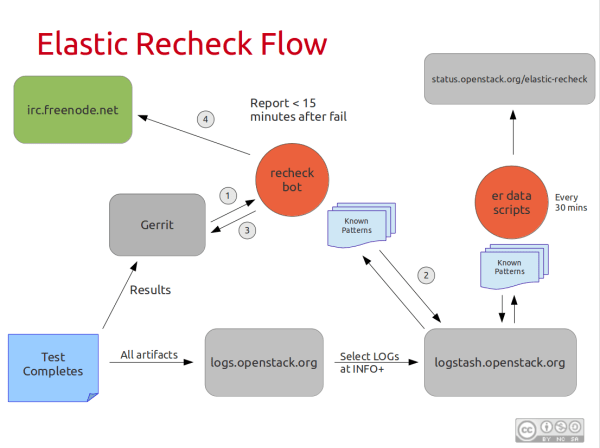 Overall this has been a huge boon towards really identifying some of the key issues we expose during normal testing. What's also been really interesting is having a system like this impacts the way that people write core project code, so that errors are more uniquely discoverable. Which is a win not only for our detection, but for debugging OpenStack in a production environment.
Overall this has been a huge boon towards really identifying some of the key issues we expose during normal testing. What's also been really interesting is having a system like this impacts the way that people write core project code, so that errors are more uniquely discoverable. Which is a win not only for our detection, but for debugging OpenStack in a production environment.